Since 2023 ever more vehicle models have begun to be connected with foundation models, and an increasing number of Tier1s have launched automotive foundation model solutions. Especially Tesla’s big progress of FSD V12 and the launch of SORA have accelerated implementation of AI foundation models in cockpits and intelligent driving.
End-to-End autonomous driving foundation models boom.
In February 2023, Tesla FSD v12.2.1, which adopts an end-to-end autonomous driving model, began to be pushed in the United States, not just to employees and testers. According to the feedback from the first customers, FSD V12 is quite powerful, allowing ordinary people who previously did not believe in and use autonomous driving to dare to use FSD. For example, Tesla FSD V12 can bypass puddles on roads. A Tesla engineer commented: this kind of driving approach is difficult to implement with explicit code, but Tesla’s end-to-end approach makes it almost effortlessly.
The development of AI foundation models for autonomous driving can be divided into four phases.
– Phase 1.0 uses a foundation model (Transformer) at the perception level.
– Phase 2.0 is modularization, with foundation models used in perception, planning & control and decision.
– Phase 3.0 is end-to-end foundation models (one “end” is raw data from sensors, and the other “end” directly outputs driving actions).
– Phase 4.0 is about heading from vertical AI to artificial general intelligence (AGI’s world model).
Most companies are now in Phase 2.0, while Tesla FSD V12 is already in Phase 3.0. Other OEMs and Tier1s have followed up with the end-to-end foundation model FSD V12. On January 30, 2024, Xpeng Motor announced that its end-to-end model will be fully available to vehicles in the next step. It is known that NIO and Li Auto will also launch “end-to-end based” autonomous driving models in 2024.
FSD V12’s driving decisions are generated by an AI algorithm. It uses end-to-end neural networks trained with massive video data to replace more than 300,000 lines of C++ code. FSD V12 provides a new path that needs to be verified. If it is feasible, it will have a disruptive impact on the industry.
On February 16, OpenAI introduced text-to-video model SORA, signaling the wide adoption of AI video applications. SORA not only supports generation of up to 60-second videos from texts or images, but it well outperforms previous technologies in capabilities of video generation, complex scenario and character generation, and physical world simulation.
Through vision both SORA and FSD V12 enable AI to understand and even simulate the real physical world. Elon Mask believes that FSD 12 and Sora are just two of the fruits of AI’s ability to recognize and understand the world through vision, and FSD is ultimately used for driving behaviors, and Sora is used to generate videos.
The high popularity of SORA is further evidence of the rationality of FSD V12. Musk said “Tesla generative video from last year”.
AI foundation models evolve rapidly, bringing new opportunities.
In recent three years foundation models for autonomous driving have undergone several evolutions, and the autonomous driving systems of leading automakers must be rewritten almost every year, which also provides entry opportunities for late entrants.
At CVPR 2023, UniAD, an end-to-end autonomous driving algorithm jointly released by SenseTime, OpenDriveLab and Horizon Robotics, won the 2023 Best Paper.
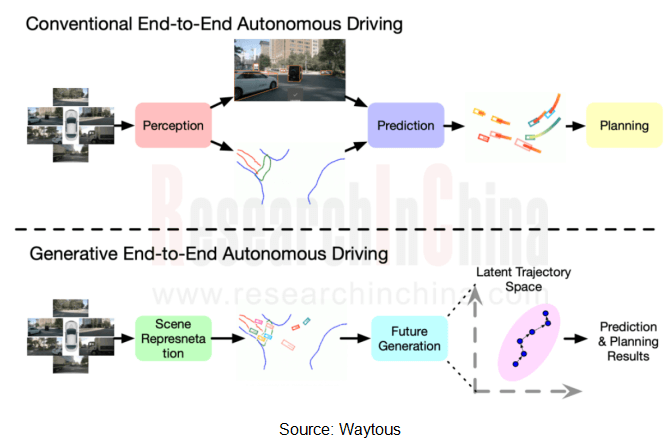
In early 2024, Waytous’ technical team and the Institute of Automation Chinese Academy of Sciences jointly proposed GenAD, the industry’s first generative end-to-end autonomous driving model which combines generative AI and end-to-end autonomous driving technology. This technology is a disruption to UniAD progressive process end-to-end solution, and explores a new end-to-end autonomous driving mode. The key is to using generative AI to predict temporal evolution of the vehicle and surroundings in past scenarios.
In February 2024, Horizon Robotics and Huazhong University of Science and Technology proposed VADv2, an end-to-end driving model based on probabilistic planning. VADv2 takes multi-view image sequences as input in a streaming manner, transforms sensor data into environmental token embeddings, outputs the probabilistic distribution of action, and samples one action to control the vehicle. Using only camera sensors, VADv2 achieves state-of-the-art closed-loop performance in CARLA Town05 benchmark test, much better than all existing approaches. It runs stably in a fully end-to-end manner, even without rule-based wrapper.
On the Town05 Long benchmark, VADv2 achieved a Drive Score of 85.1, a Route Completion of 98.4, and an Infraction Score of 0.87, as shown in Tab. 1. Compared to the previous state-of-the-art method, VADv2 achieves a higher Route Completion while significantly improving Drive Score by 9.0. It is worth noting that VADv2 only utilizes cameras as perception input, while DriveMLM utilizes both cameras and LiDAR. Furthermore, compared to the previous best method which only relies on cameras, VADv2 demonstrates even greater advantages, with a remarkable increase in Drive Score of up to 16.8.
Also in February 2024, the Institute for Interdisciplinary Information Sciences at Tsinghua University and Li Auto introduced DriveVLM (its whole process shown in the figure below). A range of images are processed by a large visual language model (VLM) to perform specific chain of thought (CoT) reasoning to produce driving planning results. This large VLM includes a visual encoder and a large language model (LLM).
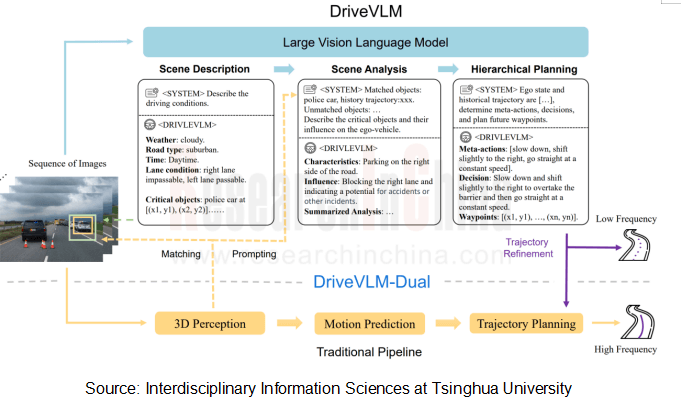
Due to limitations of VLMs in spatial reasoning and high computing requirements, DriveVLM team proposed DriveVLM-Dual, a hybrid system that combines advantages of DriveVLM and conventional autonomous driving pipelines. DriveVLM-Dual optionally combines DriveVLM with conventional 3D perception and planning modules, such as 3D object detector, occupancy network, and motion planner, allowing the system to achieve 3D localization and high-frequency planning. This dual-system design, similar to slow and fast thinking processes of human brain, can effectively adapt to changing complexity of driving scenarios.
AI and cloud companies attract attention as foundation models emerge.
As AI foundation models emerge, computing power, algorithm and data are indispensable. AI companies (iFLYTEK, SenseTime, Megvii, etc.) that are good at algorithms and have a large reserve of computing power, and cloud computing companies (Inspur, Volcengine, Tencent Cloud, etc.) with powerful intelligent computing centers, come under a spotlight of OEMs.
In the field of AI Foundation Model, SenseTime has deployed cockpit multimodal foundation model SenseChat-Vision, Artificial Intelligence Data Center (AIDC, with computing power of 6000P), and autonomous driving foundation model DriveMLM. In early 2024, SenseTime launched DriveMLM and achieved good results on CARLA, the most authoritative list of closed-loop test. DriveMLM is an intermediate solution between modular and end-to-end solutions and is interpretable.
For collection of autonomous driving corner cases, Volcengine and Haomo.ai work together to use foundation models to generate scenarios and improve annotation efficiency. The cloud service capabilities provided by Volcengine help Haomo.ai to improve the overall pre-annotation efficiency of DriveGPT by 10 times.
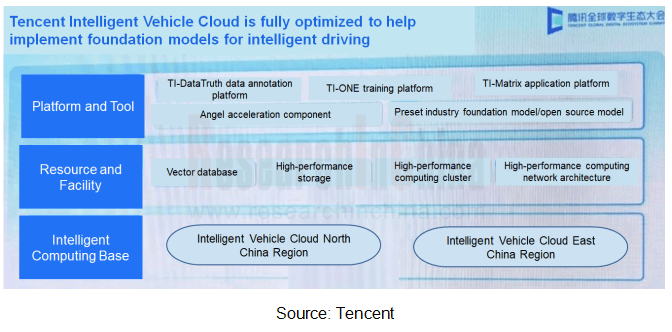
In 2023, Tencent released upgraded products and solutions in Intelligent Vehicle Cloud, Intelligent Driving Cloud Map, Intelligent Cockpit and other fields. In terms of computing power, Tencent Intelligent Vehicle Cloud enables 3.2Tbps bandwidth, 3 times higher computing performance, 10 times higher communication performance, and an over 60% increase in computing cluster GPU utilization, providing high-bandwidth, low-latency intelligent computing power support for training foundation models for intelligent driving.
As for training acceleration, Tencent Intelligent Vehicle Cloud combines Angel Training Acceleration Framework, with training speed twice and reasoning speed 1.3 times faster than the industry’s mainstream frameworks. Currently Bosch, NIO, NVIDIA, Mercedes-Benz, and WeRide among others are users of Tencent Intelligent Vehicle Cloud. In 2024, Tencent will further strengthen construction of AI foundation models.

{kind=link}